
点睛:手写财富 记忆 署书:乔惠民 中国国土经济学会研究室主任、国土名片网总编辑
导读:国土名片网小编芬儿、李新宇
西波手写文字识别的元学习方法
何翠玲,杨柱元,唐 轶,蒋 作
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
在中华民族大家庭中,彝族不仅历史悠久,而且文化丰富.西波文不仅是记录彝族古老典籍的一种特殊古文字,而且是彝族珍贵的文化遗产[1].新中国成立后,尽管党和政府加大力度对西波文进行保护和整理,但由于年代久远、流传较少等因素.西波文的使用越来越少,并存在着逐渐消亡的迹象[2].西波文的保护刻不容缓,其保护手段和方法需要根本性的改变.若能实现对其智能识别,则不仅有助于对彝文古籍进行分类和保存,而且为彝族文明的传承和发展提供现代智能技术的支持.
西波文字的智能识别难度大,罕有研究.一方面,西波手写文字书写随意性大,没有统一的规范,这使得西波手写文字识别成为一个极具挑战的问题.其主要表现为.
1) 西波手写文字收集困难,缺乏成熟的样本库.手写样本库的数量和质量是西波手写文字识别成功的关键因素,直接决定着识别效果.
2) 西波手写文字字体、字形多样,没有统一标准.不同地区书写方式不同,形式和格式各有不同,增加了智能识别难度.
另一方面,西波文字仅在中国西南局部传承,不是现行主流语种.因此,尚未引起人工智能领域的关注.然而,该文字记录了大量彝族历史、宗教、沿袭等文献.这对民族及历史研究具有极其重要的研究价值.因此,西波文字的智能识别问题不仅具有重要的人文价值,更是一个极具挑战性的手写文字识别问题.
通用彝文智能识别问题已有不少成果,然而西波手写文字识别尚未见报道.目前常见的彝文识别有图像分割[3]、组合特征分类[4]和卷积神经网络[5]等方法.由于西波文字年代久远、流传较少、古籍退化破损形象严重.很难获取西波文字样本,因此常见的智能识别方法难以直接应用.
针对小样本的西波手写文字识别问题.本文利用MANN模型进行西波手写文字识别.MANN用LSTM(long shot-term memory,长短期记忆网络)[6]做控制器,最近最少使用访问模块(LRUA,least recently used access)做外部记忆.控制器LSTM将学习得到的内容通过读写头与外部记忆进行交互.LSTM学习得到的内容通过读写头存储在外部记忆中,并产生相关密钥gt.LSTM进行新的学习时,通过密钥gt查询、遗忘门ft决定是否从外部记忆读取学习.当LRUA查询到相关内容时,遗忘门ft关闭,直接从外部记忆读取相关内容进行学习,若没有查询到相关内容,则遗忘门ft打开,将LSTM学习到的内容存储在外部记忆.
通过在不同样本集上比较LSTM识别精度可以发现,在增强样本集上,LSTM识别率略有提高,但是提高程度不明显.这表明简单的样本增强技术不能改善LSTM识别精度.但使用MANN[7],识别精度明显提高.同样,元学习方法也能改善小样本学习精度不高的问题.本文提出了基于记忆的元学习方法,结合了记忆和元学习两者的优点.在理论上,本文的方法可以进一步改善小样本带来的西波手写文字识别困难的问题.
1 研究背景和介绍
1.1 深度学习
深度学习是人工智能研究领域中新兴的研究方向,其典型代表包括卷积神经网络和循环神经网络.卷积神经网络在图像识别和目标检测等领域取得了巨大的成功.在ILSVRC2012测试中,来自多伦多大学Alex Krizhevsky团队[8]提出的AlexNet卷积神经网络将top-5错误率降到15.3%.在PASCALVOC2012数据集上,Li等[9]提出的R-FCN模型达到了82%的目标检测准确率.循环神经网络和它的改进版LSTM常用来处理带有时间序列信息的问题.在自然语言处理中,Jia等[10]使用循环神经网络完成了将自然语言转换为机器语言的任务.Albahar[11]利用Dropout的正则化方法优化RNN(recurrent neural network,循环神经网络)和LSTM模型.在语言建模、语音识别和机器翻译中,证明了正确使用正则化,可以大大减少RNN和LSTM的过拟合.
深度学习方法在手写数字、手写字母、手写文字识别领域也有很多应用.在手写数字识别领域中,2006年,Das等[12]提出利用MLP(multi layer perceptron,多层感知器)对含有88个特征的特征集手写阿拉伯数字进行识别.通过收集300个不同年龄段和性别的10个光学扫描手写数字样本,形成 3 000 位样本的数据集上进行实验.其中 2 000 样本为训练集,1 000 为测试集,识别率达到94.93%.2012年,Sharam等[13]利用支持向量机在Optdigits数据集上得到了98%的手写数字识别率.2017年,Ashiquzzaman等[14]利用卷积神经网络进行手写数字识别.在CMATERDB3.3.1阿拉伯手写数字数据集上进行测试和训练.整个数据集包含 3 000 张图像,其中,2 000 作为训练样本,1 000 作为测试样本.最终达到97.4%的准确率.2019年,Mandal等[15]利用胶囊网络分别在Bangla Digits、Devanagari Digits、Telugu Digits、Bangla Basic Character和Bangla Compound Characters的数据集上得到了97.75%、96.60%、97.80%、96.20%和94.40%的识别率.
在手写字母识别领域中,2016年,Maziar等[16]使用ECOC(error correcting output coding,纠错输出编码)方法得到89.35%的波斯手写字母识别率.2018年,Vinaychandran等[17]利用深卷积神经网络对使用交叉描写 (例如手迹,摩擦)创建的图像水印进行识别.在 1 060 502 个水印复制品数据集上得到96%的识别率.2019年,Khan等[18]利用K最近邻(KNN)和神经网络(NN)对单个字母进行识别.在来源于普什图语的 4 488 张图像数据集上,KNN可以达到70.05%的识别精度,而NN达到72%的识别精度.
在手写文字识别领域中,2013年, Dan等[19]使用深层宽池最大卷积神经网络(MPCNN)进行手写汉字识别.并在HWDB1.1数据集上,将错误率下降到4.215%.2015年,Dapeng等[20]利用弱监督学习进行相似字符的识别.对CASIA汉字数据集进行评估,达到了98.28%的识别率.2017年,Yoshua等[21]利用传统的DirectMap(direction-decomposed feature map,方向分解特征图)和CNN(convolutional neural network,卷积神经网络)相结合的方法,将HCRR(Chinese character recognition,手写汉字识别)准确性提高到96.95%.2018年,Li等[22]提出一种称为全局加权平均池化的CNN技术进行手写汉字识别.在ICDAR-1023离线HCCR.数据集上,仅需 6.9 ms 就达到97.1%的识别精度.
1.2 小样本学习介绍
由于西波手写文字没有成熟的手写样本库,所以西波手写文字识别是1个小样本问题.目前,能够很好的解决小样本问题有以下3种方法:
①正则化:限制模型复杂性提高推广性能.支持向量机SVM是其中的典型代表.SVM可用于处理非线性回归和分类问题,特别是在处理小样本学习问题时,SVM具有很强的推广性能.但是,SVM算法运算复杂度高,不适用于大规模训练样本问题.同时,核函数的选择问题,也是制约SVM性能提升的一大问题.
②数据增强:增加数据量以提高推广性能.利用数据增强技术扩大样本数量,能提高模型的范化能力、提升模型的鲁棒性.但存在学习缓慢、训练时间长等不足之处.
③元学习:利用外部信息提高推广性能.元学习(meta learning)是学习如何学习,利用元数据改善机器学习效率的一种新型学习方法.
常见元学习方法有以下3种:
1) 度量学习(metric learning)方法:度量学习的主要目的是寻求最佳的距离度量方法,以适应当前学习样本的几何结构或相似性关系.较之固定的度量,如欧氏距离等,从样本中学习得到的度量能更精准的反映样本间的临近关系或相似关系.
2) 使用具有外部或内部记忆:通过以往的经验来学习,在神经网络中添加记忆模块进行实验.
3) 显示优化模型参数来快速学习(基于Finetune):基于Finetune,在获得一定量的标注数据后,基于一个基础网络进行微调.基于Finetune的方法相对训练速度较快,训练数据较少,但是基础网络需通过含有大量标签的数据集来获得.
2 模型
2.1 LSTM
2.1.1 循环神经网络
循环神经网络是一类具有动态状态的机器.也就是说,它们具有的状态演变既取决于系统的输入又取决于当前状态.循环神经网络的模型如图 1所示.
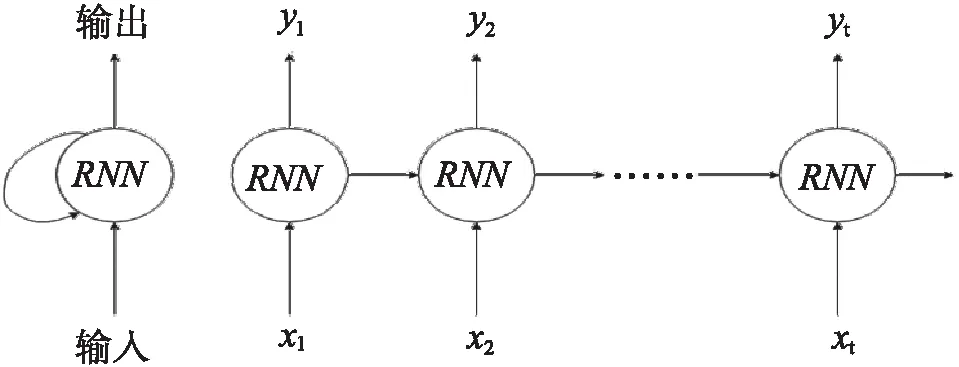
图1 循环神经网络(Xt表示输入数据,yt表示输出)
循环神经网络的一项关键创新是长短时期记忆网络(LSTM) (Hochreiter[24]和Schmidhuber),主要解决“梯度消失和梯度爆炸灵敏度”问题,LSTM网络模型如图 2所示.

图2 长短时期记忆网络(Xt表示输入数据,yt表示输出)
其中每个LSTM的展开图[25]如图3.

图3 LSTM展开图
ft为遗忘门:控制遗忘多少信息,计算方式如下[23]:
ft=σ(Wf.[ht-1,xt]+bf)
.
( 1 )
it为输入门:记忆当前状态的某些信息,计算方式如下[23]:
it=σ(Wi.[ht-1,xt]+bi)
.
( 2 )
ht为短期记忆,ct为长期记忆,计算方式分别为[23]:
ht=ot*tan h(ct)
.
( 3 )
( 4 )
( 5 )
ot为输出门,计算方式如下[23]:
ot=σ(Wo.[ht-1,xt]+bo)
.
( 6 )
2.2 记忆增强网络
2.2.1 外部记忆
为了神经网络有更大的存储空间,我们可以引入记忆单元.将一些信息保存在记忆单元中,在需要时再进行读取,这样可以有效地增加网络容量.这个记忆单元一般称为外部记忆.
2.2.2 记忆增强网络
一般来说,神经网络的存储空间相对较小.为此,我们可以加入结构化的记忆模块来增加网络的存储空间.基于神经网络加入外部记忆单元的模型称为记忆增强网络,模型如图4所示.

图4 记忆增强网络
记忆增强网络一般由以下几个模块构成.
a) 控制器LSTM:负责信息处理,同时通过读写模块和外部记忆进行交互.
b) 外部记忆单元R:信息存储在外部记忆单元中,且外部记忆可分为很多记忆片段.记忆片段一般用向量表示,外部记忆单元用一组向量rt=[r1,r2,…,rn]表示.向量的组织方式一般为集合,树,栈或队列等形式.大部分信息存储在外部记忆单元中,不需要全程参与控制器的运算.
c) 读取模块M:根据控制器生成的查询向量qm,从外部记忆单元中读取相应的信息m=M(m1,n,qm).
d) 写入模块W:根据控制器生成的查询向量qw和要写入的信息∂来更新外部记忆w=M(m1:N,qw,∂).
长短时期记忆网络LSTM作控制器,最近最少使用访问LRUA模块进行外部记忆的存储和读取.
在深度学习中,为了最小化数据集D上的学习成本L,通常只需优化参数β.但是,对于元学习,需要优化参数β以降低服从分布P(D)的数据集上的期望学习成本:
β=arg minβED~P(D)[(L(D,β))].β=arg minβED~P(D)[(L(D,β))].
( 7 )
在MANN模型中,数据集为D={dt}={(xt,yt)}.yt既是目标类别标签,又以时间偏移的方式与xt一起输入;也就是说,模型输入序列为(x1,0),(x2,y1)…(xt,yt-1).因此,对于MANN模型,标签需进行混洗.混洗是将任务数据集D={dt}={(xt,yt)}的表现形式重新绑定为D1={dt}={(xt,yt-1)}的表现形式.它可以防止网络在权重上缓慢学习并进行样本类别绑定.样本类别绑定后,将样本数据信息保存在外部记忆单元中.在后面的学习中,如果遇到相关信息,则直接从外部记忆单元中读取学习(见图5).
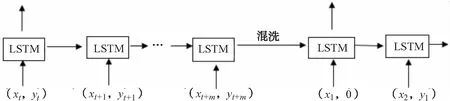
图5 进行样本类别绑定

图6 记忆增强网络
图 6中,样本数据集D1={dt}={(xt,yt-1)}作为MANN模型的输入,并通过控制器LSTM学习.在特定时间内学到的类别标签信息通过读写头存储在外部记忆单元中.在随后的学习过程中,如果遇到学习过的相关任务样本数据xt,则对外部记忆进行相关查询并快速识别.
控制器LSTM使用读写头与外部记忆单元R进行交互,读写头分别从外部记忆单元R中查询或存储记忆.给定一些输入xt,控制器LSTM产生一个密钥gt,然后存储在外部记忆单元Rt的空位置,或用于已存储过的外部记忆单元中查询特定的外部记忆i,即Rt(i).当查询外部记忆单元Rt时,使用余弦相似性度量来寻址向量mt,
(8)
(9)
读取向量mt可定义为外部记忆向量Rt(i)的凸组合:
( 10 )
在本文提出的模型中,用LRUA模块进行记忆的存储和读取.LRUA模块是一个纯内容的记忆存储器,它将记忆存储在最近或最少使用的位置,该模块强调最近或最少信息的准确编码,以及基于内容的查询.新信息存储在最近或最少使用的位置,并用新信息代替旧信息进行外部记忆单元更新.

( 11 )

( 12 )
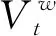
( 13 )

( 14 )
信息可以存储在归零存储器或先前使用的存储器中;如果是后者,则最少使用记忆被新信息代替.
3 实验
3.1 数据
西波手写文字字符类似于汉字方块字符,其书写规范、大小、字体等相对一致.但西波手写文字由于受潮,烟熏等原因,出现笔记变弱,断笔,粘连,污点等现象.

图7 西波手写文字
对收集到的西波手写文字进行人工分割,得到如图 7的文字样本.西波手写文字数据集有150张图片,分为5类别,每类别有30张图片.其中,120张图片为训练集,每类别有24张图片;30张为测试集,每类别有6张图片.为了减少实验计算时间,将图像大小缩小到30×30像素.
3.2 实验和评估
为识别西波手写文字,建立含有6层的LSTM神经网络.第1层LSTM具有128个神经元,第2层神经元个数为64,第3层神经元个数为128,第4层神经元个数为64,第5层神经元个数为128,每层LSTM的激活函数为relu函数.第6层为全连接网络层,神经元个数为5,激活函数为softmax函数.具体设置如表 1所示.

表1 LSTM模型参数
在含有120张西波手写文字图片的训练集上进行训练,总共训练4 000次,分40轮训练,每轮迭代100次.将训练好的模型在含有30张西波手写文字图片的测试集进行测试,测试得到的结果如表2所示.

表2 LSTM初始数据实验结果
由表 2可看出,长短时期记忆网络LSTM的识别精度只有26%,却花了 3 954.087 s.随后,将训练集进行随机缩放,并设置缩放比例为0.2.将原有的训练集分别进行1.2倍,1.5倍,2倍的数据增强.利用上述描述的LSTM模型在数据增强样本训练集上进行相同训练,在原有的测试集上进行测试,测试得到的结果如表 3所示.

表3 数据增强实验结果
由上述的实验结果可知,在数据增强样本数据集上进行训练,测试得到的识别精度相对提高了7%,并且训练时间增加.长短时期记忆网络LSTM对手写西波文识别性能不佳.
构建12层卷积神经网络,重复LSTM实验.第1层卷积神经神经网络的神经元个数为32,卷积核个数为2,滑动步长为2.第2层为池化层,其池化大小为2,第3层,第5层,第7层的卷积神经网络的神经元个数分别为64,32,64,卷积核个数,滑动步长和第1层卷积神经网络的设置相同.第4层,第6层,第8层为池化层,并与第2层池化层的设置相同.第9层为flatten层,第10层为全连接层,神经元个数为5,激活函数为softmax函数.具体设置如下:
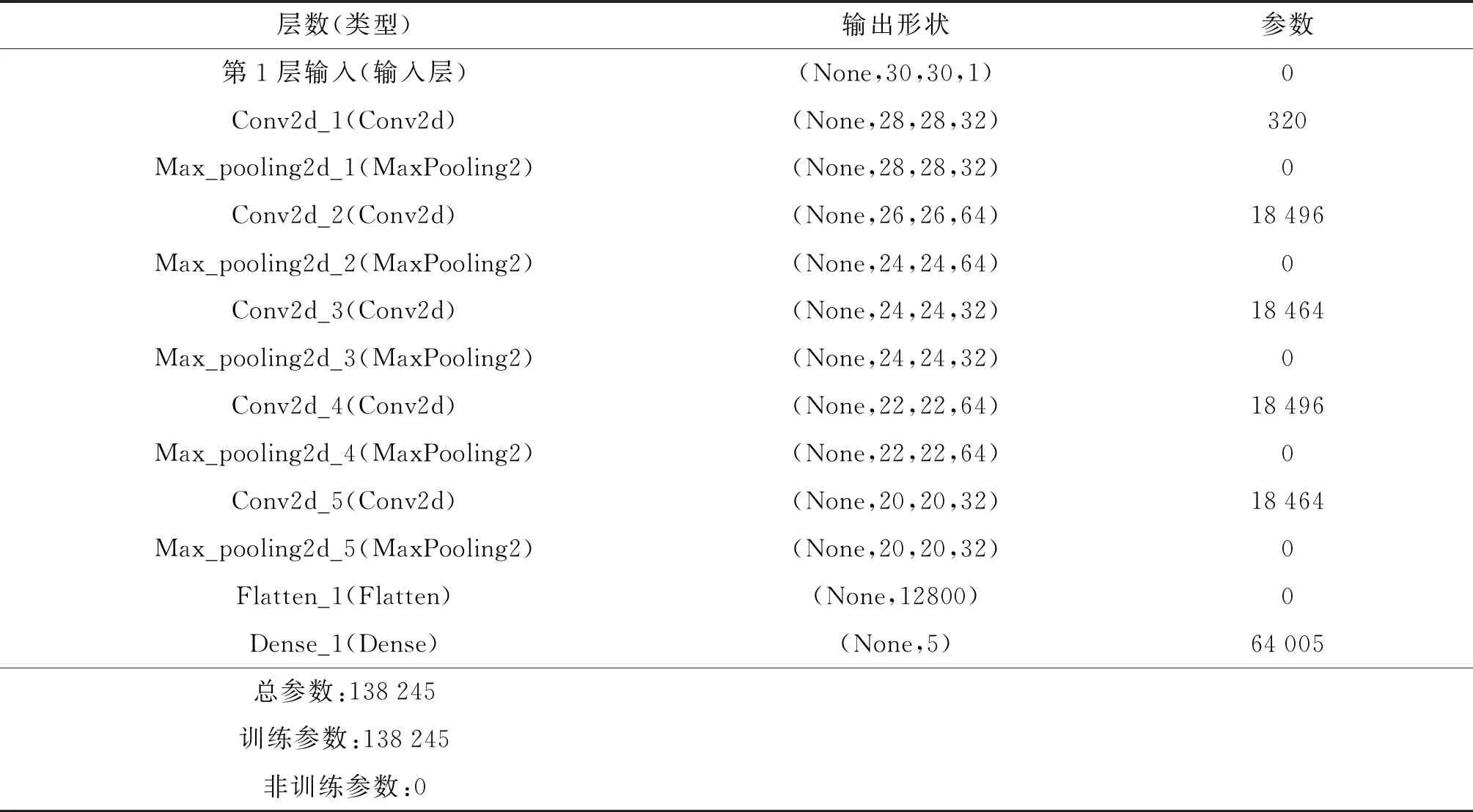
表4 CNN模型参数
卷积神经网络得到的实验结果如表 5所示.

表5 CNN实验结果
由以上的实验结果可知,深度学习的LSTM模型,CNN模型对小样本的西波手写文字数据集的识别效果并不理想.即使对西波手写文字进行数据增强,识别效果也没有得到改善.对2.2节描述的MANN模型进行相同迭代训练.并在含有30张图片的测试集上进行测试,得到的实验结果如表(6)所示:

表6 LSTM、CNN、MANN实验结果
表 6说明,LSTM模型,CNN模型对小样本的西波手写文字数据集识别精度最高达到36%,并花费大量时间进行训练.由于深度学习对识别任务需要大量的数据进行广泛迭代训练,才能达到理想的效果.因此,在小样本的西波手写文字识别任务中,深度学习并不是一个理想的选择.相反,元学习对小样本的西波手写文字识别效果比较理想.MANN模型只需深度学习一半的训练时间,识别精度就可提高到79%.
4 结语
本文将西波手写文字识别问题归结为小样本学习问题.为有效处理该问题,引入了元学习方法以提高识别精度.LSTM模型添加一个外部记忆存储模块,对小样本的西波手写文字进行训练和测试.实验表明,元学习方法在小样本的西波手写文字数据集上识别效果良好.它仅需要LSTM、CNN的一半训练时间,识别精度就可提高43%.本文证明了MANN在小样本任务中显示出的性能优于LSTM、CNN的性能.